ในแวดวงบัญชีและการเงิน มีความคิดหาวิธีอ่านข้อมูลในบิลกระดาษมาบันทึกข้อมูลแบบอัตโนมัติมานานแล้ว อุปสรรคสำคัญอยู่ที่รูปแบบของบิลที่เรียกว่าร้อยพ่อพันแม่ ไม่มีมาตรฐาน จนกลายเป็นแค่งานทำเพื่อใช้ภายในองค์กร ทำได้แค่รูปแบบบิลเท่าที่รู้จัก ถึงแม้จะประสบความสำเร็จก็ไม่สามารถนำไปใช้กับที่อื่น การถ่ายทอดความรู้จึงถูกจำกัด
OCR
เทคโนโลยีแปลงรูปภาพในข้อความที่ใช้กันปัจจุบันคือ OCR เช่น Tesseract ที่เป็น opensource และสนับสนุนโดย Google ช่วยปรับปรุง สามารถแปลงภาพสแกนจากหนังสือแทบทุกภาษาในโลกให้กลายเป็น e-book แต่เมื่อนำมาประยุกต์ใช้กับบิล ถึงแม้ว่าจะสามารถแปลงข้อความได้ถูกต้อง กลับมีความยากลำบากในการแยกแยะข้อความว่าส่วนไหนหมายถึง วันที่, เลขที่เอกสาร, จำนวนเงินสุทธิ, มูลค่าภาษี ซึ่งผลลัพธ์โดด ๆ ที่ได้จาก OCR บอกแค่ตำแหน่งบนกระดาษ
การจะบอกว่าข้อความนี้เป็นวันที่ จะต้องพิจารณาความสัมพันธ์กับข้อความข้างเคียงด้วย เหมือนกับการที่มนุษย์ทั่วไปดูบิลแล้วบอกได้ เช่น ต้องมีคำว่า “วันที่” หรือ “Date” แต่ต้องไม่ใช่คำว่า “วันที่ครบกำหนด” หรือ “Due Date” เป็นต้น
หากจะต้องเขียนโค้ดเพื่อตรวจหาความสัมพันธ์เหล่านี้ เมื่อคิดถึงความหลากหลายรูปแบบบิล จึงเป็นงานไม่จบสิ้น กลายเป็นว่าการพัฒนาตรงนี้มักเป็นงานเฉพาะใช้กับที่ใดที่หนึ่ง เมื่อเจอบิลรูปแบบใดรูปแบบหนึ่งจำนวนมากจนคุ้มค่าที่จะพัฒนาให้อ่านฟอร์มแบบนั้นอัตโนมัติ
ความย้อนแย้งที่มักเกิดขึ้น เอกสารที่กิจการนั้นเป็นผู้จัดทำด้วยโปรแกรม เช่น ใบกำกับภาษี, ใบเสร็จรับเงิน เก็บเป็นข้อมูลอยู่แล้ว ก็ไม่จำเป็นต้องพึ่งเทคโนโลยี OCR มาอ่านจากกระดาษกลับเข้าไป ดังนั้นจึงเหลือแต่เอกสารภายนอกที่เกิดจากการซื้อสินค้า หรือจ่ายค่าบริการต่าง ๆ ที่ได้รับใบกำกับภาษีหรือใบเสร็จในรูปแบบกระดาษ การลงทุนทำระบบอ่านบิลอัตโนมัติจึงมักถูกตั้งคำถามถึงความคุ้มค่า กับข้อจำกัดที่ขึ้นอยู่กับรูปแบบของบิล และความไม่แน่นอนหากผู้ออกบิลเปลี่ยนรูปแบบในอนาคต
Geneative AI
แนวทางของ Donut ไม่ใช้เทคนิค OCR แต่ใช้ Vision Encoder Decoder ใช้ตัวอย่างรูปภาพบิลตัวอย่างสอนให้เข้าใจองค์ประกอบ เหมือนกับ AI ที่สามารถแยกแยะรูปภาพหมา แมว และสัตว์ต่าง ๆ ก็ต้องถูกสอนด้วยภาพของสัตว์เหล่านั้น นอกจากนี้ยังใช้ SynthDog มาประกอบเพื่อให้เข้าใจตัวอักษรที่อยู่ในภาพ (base model ถูกสอนให้เข้าใจ ภาษาอังกฤษ, จีน, ญี่ปุ่น, เกาหลี)

ตัวอย่างของการประยุกต์ใช้งาน Donut ได้แก่
classification แยกแยะประเภทเอกสาร เช่น “receipt” (สีแดง ในรูป)
vision-question-answer ตอบคำถามจากข้อมูลในเอกสาร เช่น “choco mochi ราคาชิ้นละเท่าไหร่?” (สีฟ้า ในรูป)
parsing สะกัดข้อความสำคัญ ออกมาเป็นข้อมูล (สีเขียว ในรูป)
โดยเฉพาะการใช้งาน parsing นี่แหละ ที่คาดหวังว่าสามารถเอามาใช้แทน OCR ที่ยังไปไม่ถึงฝั่งฝัน ที่จะทำให้เป็น general purpose รองรับบิลภาษาไทย และกลุ่มที่น่าจะได้ประโยชน์ไม่ใช่ผู้ประกอบการ แต่เป็นสำนักบัญชี
Donut finetuned on invoices
ใน Hugging Face มี demo space ของ to-be (Toon Beerten) เอา Donut base model มาสอน (train) เพิ่มเพื่อทำ finetune ด้วยตัวอย่างรูปภาพของ invoice กลายเป็น AI ตัวใหม่ ที่เข้าใจรูปแบบบิลที่เป็นฟอร์มจริง ๆ ไม่ใช่สลิปใบเสร็จรับเงิน
ในนั้นบอกว่า ใช้ภาพไม่กี่พันภาพ ใช้เวลาประมาณ 4 ชม. ด้วย NVIDIA RTX A4000
ภาพฟอร์มบิลตัวอย่างใน space นั้นมีบิลภาษาไทยรวมอยู่ด้วย จากภาพด้านล่าง ผมสังเกตเห็นว่า
สามารถเข้าใจวันที่ ที่เป็นปี พ.ศ.
อ่านข้อความสำคัญได้ถูกต้อง เช่น เลขที่, จำนวนเงินรวม

Thai invoices testing
ผลจากการทดสอบเบื้องต้นทำให้รู้สึกมีความหวัง แม้ว่าแค่ทดสอบด้วย free tier ของ Hugging Face ใช้เวลา 40 วินาที (ถ้าใช้ GPU จะเหลือเพียง 2 วินาที) ผมจึงท้าทายด้วยภาพของบิลที่ AI ไม่เคยรู้จักมาก่อน เป็นรูปภาพบิลที่แม้แต่คนก็ยังอ่านยาก เช่น หมึกจาง และ ลายมือเขียน
ผลลัพธ์ที่ได้มาต้องบอกว่า “นายแน่มาก!”
ภาพแรก
เป็นบิลชั้นสำเนาเคมี ที่ตัวอักษรค่อนข้างจาง ผลลัพธ์อ่านได้ถูกต้องทั้งหมด
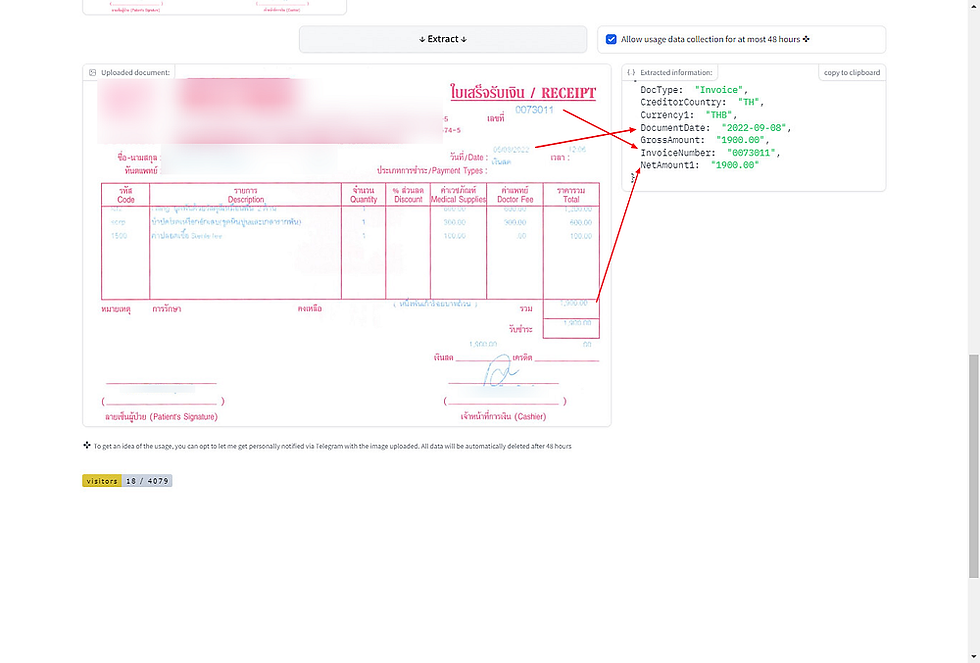
ภาพที่สองเป็นบิลเขียนมือ ลายมือพออ่านได้ง่าย แต่จุดสังเกตอยู่ตรงที่ วันที่ ใช้ปี พ.ศ. แบบย่อเป็นเลขสองตัว และเดือนเขียนเป็นชื่อย่อ “ก.ย.”
AI ไม่รู้จักรูปแบบบิลที่มี เล่ม/เลขที่
จำนวนเงิน เศษสตางค์ที่อ่านจุดไม่ชัด แปลงไม่ถูก
วันที่ เกือบถูก เดือนที่เป็นชื่อย่อแปลงเป็นเดือน 9 ได้ แต่เลขวันที่ผิด

ภาพที่สาม
บิลเขียนมือที่คนทั่วไปยังอ่านแทบไม่ออก นอกจากวันที่เขียนชื่อเดือนเป็นตัวย่อแล้ว ช่องจำนวนเงินก็แยกช่องระหว่างบาทกับสตางค์ด้วย ปรากฏว่า AI อ่านผิดทั้งหมด
สังเกตว่าฟอนต์ของคำว่า No ไม่สามารถ detect เลขที่ได้
พยายามอ่านลายมือจำนวนเงินได้เกือบถูก 147042 → 147049 เลข 2 เขียนหัวตัวหางสั้นคล้ายเลข 9 มาก ถ้าเป็นคนอ่านต้องใช้วิธีสังเกตเลข 2 ตำแหน่งอื่นมาเทียบเคียง

The mountain’s so high
วันนี้ฟ้าสวยจนอยากถ่ายรูปเก็บไว้
หากมาจากถนนลาดพร้าวเลี้ยวเข้าโชคชัยสี่ ตรงมาเรื่อย ๆ สักพักหนึ่งจะสังเกตเห็นเจดีย์สูงตระหง่านในซอย 39 เป็นที่ตั้งของตำหนักเจ้าแม่กวนอิม ตรงข้ามกับเจดีย์มีร้านกาแฟ “อั่ง-ตี๋” ผมมักมานั่งทำงานและครุ่นคิดที่นี่

Valley’s deep and the mountain’s so highIf you want to see God you’ve got to move on the other side — Baclay James Harvest
เกือบสิบปีที่แล้ว ผมมักพาเด็ก ๆ มาที่ตำหนักแห่งนี้ วันเสาร์-อาทิตย์ที่ตำหนักเปิดให้ขึ้นไปถึงยอดเจดีย์ได้ บางทีความเชื่อต้องการใกล้ชิดพระเจ้าด้วยการหาทางไปให้สูงที่สุดเป็นของมนุษย์ทุกเชื้อชาติ
วันศุกร์ที่แล้ว ตอนตื่นนอน ลุกขึ้นด้วยอาการเจ็บแปลบที่หัวเข่าจนเดินเขยก อาจเป็นเสียงเตือนเบา ๆ จากสังขาร
วันนี้ฟ้าสวย ถ้าขึ้นไปบนยอดนั้นจะรู้สึกอย่างไร ผมนวดคลึงหัวเข่าเบา ๆ ใจครุ่นคิดถึง Generative AI
อ้างอิง
Tesseract OCR https://github.com/tesseract-ocr/tesseract
Donut paper https://arxiv.org/abs/2111.15664
Donut base model https://huggingface.co/naver-clova-ix/donut-base
Donut SynthDog https://github.com/clovaai/donut/tree/master/synthdog
Demo invoice extraction https://huggingface.co/spaces/to-be/invoice_document_headers_extraction_with_donut
댓글